Over ons
Hoe
Het volgende schema geeft de architectuur van het systeem van Erfgoedplus.be weer:
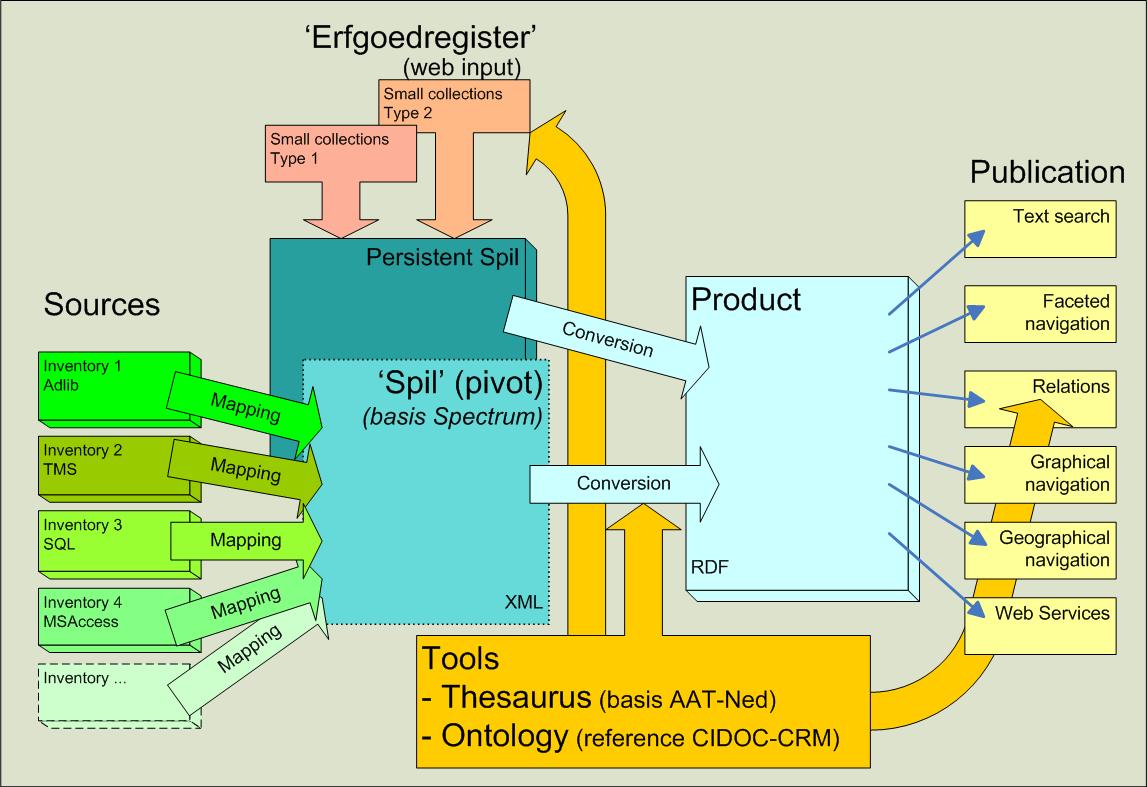
De verschillende onderdelen:
- databank: blauwe blokken centraal ('Spil' formaat en ‘Product’ of navigeerbaar formaat) waar de gegevens over het erfgoed gestandaardiseerd opgeslagen worden. Het Spil formaat is gebaseerd op de Spectrum standaard voor museumdocumentatie, het Product formaat wordt afgestemd op de noden van de navigatie.
- invoer: de gegevens kunnen op twee manieren ingebracht worden in Erfgoedplus.be: ofwel door bestaande databanken te converteren, ofwel door het Erfgoedregister waarmee de beschrijvingen van erfgoedobjecten rechtstreeks in de databank kunnen worden ingevoerd
- links bij ‘Bronnen’: bestaande collecties die via ‘mapping’ ingevoerd worden in de databank. Collectiebeheerders blijven hun eigen systeem gebruiken, en maken regelmatig een export van hun gegevens voor update van de informatie in Erfgoedplus.be via conversie. Het Spil formaat is hierbij slechts een tussenstap in de conversie naar Product formaat.
- boven bij ‘Erfgoedregister’: rechtstreekse invoer in de databank in Spil formaat voor beheerders van kleinere collecties. Zij kunnen hun inventaris gebruiken en onderhouden via hun webbrowser. De gegevens worden opgeslagen in een XML database in Spil formaat ('Persistent Spil').
- onderaan bij ‘Instrumenten’: standaardisering van de gegevens via thesaurus en ontologie, gebruikt bij invoer, conversie en navigatie. De Getty AAT (Art & Architecture Thesaurus), Spectrum (Collections Trust) en CIDOC-CRM (Conceptual Reference Model - ISO 21127:2014) zijn de voornaamste standaarden gebruikt voor het modelleren en coderen van de data.
- rechts bij de 'Publicatie': de mogelijke publicatiediensten zoals in www.erfgoedplus.be gebruikt
- bijkomend worden de gegevens in Spil formaat geconverteerd naar het Europeana EDM formaat en ter beschikking gesteld in een Repository voor OAI-PMH harvesting
- collectiebeschrijvingen zijn aangemaakt in Archiefbank Vlaanderen en zijn daar consulteerbaar d.m.v. koppelingen, zowel in het Erfgoedregister als in www.erfgoedplus.be
- waar mogelijk worden in www.erfgoedplus.be vanuit de objectbeschrijvingen koppelingen gemaakt met de relevante objecten in andere on-line databases: AAT, KIK, Inventaris Onroerend Erfgoed, Wikipedia, het MOT, enz.
Software
Het bouwen van een dergelijk complex en toekomstgericht platform vereist heel wat technische componenten en een doorgedreven geïntegreerde implementatie.
De 'Spil' (en ‘Persistente Spil’ databank) wordt op twee manieren gevoed:
- door de aanlevering (in XML) van externe collecties die dan een kwaliteitscontrole en conversie doorlopen. Hiervoor worden Netkernel 1060 componenten gebruikt. Deze of bijkomende Netkernel 1060 componenten worden tevens gebruikt voor het aanmaken van de 'Product' databank (RDF triples) voor de ontsluiting.
- de 'Persistente Spil', of centrale inventarisdatabase voor kleinere collecties is opgeslagen in een Oracle Berkeley DBXML. Ze wordt gevoed door rechtstreekse invoer via het Erfgoedregister, waarvoor formulieren werden ontwikkeld met Orbeon Forms.
Aangeleverde beelden, documenten en multimedia bestanden vanuit externe collecties alsook de bestanden ingevoerd via het Erfgoedregister worden beheerd in Alfresco met als onderliggende database MySQL.
De woordenlijsten, thesauri en ontologiën worden beheerd met FluidOps Information Workbench met als onderliggende RDF database Sesame triple store. Thesaurustermen uit de Getty AAT worden direct gekoppeld aan de Linked Open Data versie op de Getty servers.
Website - www.erfgoedplus.be
Voor de ontsluiting via het web worden volgende componenten gebruikt:
- Drupal (een Open WCMS) voor het beheer van de statische inhoud van de website met als onderliggende database MySQL en PHP als scripting taal.
- Fuseki triple store voor de RDF data, die kan bevraagd worden d.m.v. SPARQL queries en die gebruikt wordt voor het tonen van de data in de detailpagina's.
- Elasticsearch voor de indexering en het zoeken van de data in JSON formaat. Die worden gebruikt voor de navigatie, het zoeken en resultatenlijsten.
- De zoek- en navigatiewidgets zijn gemaakt met JavaScript.
Het OAI-PMH repository wordt beheerd met de open source Repox software, ontwikkeld in het kader van het Europese TELplus project
Het geheel draait op intel-gebaseerde machines onder Windows Server 2008 met applicatie server Tomcat.
De architectuur werd ontworpen en het systeem ontwikkeld in samenwerking met het bedrijf Amplexor uit Leuven. Het content gedeelte van de website (Drupal) werd in 2010 uitgewerkt door Artspot.